class: center, middle, inverse, title-slide # Mixed Models in R ## A Practical Introduction ### Henrik Singmann (University of Warwick)<br/>Twitter: <a href='https://twitter.com/HenrikSingmann'><span class="citation">@HenrikSingmann</span></a> ### Jul 2019 --- # Mixed Model Analysis Steps for running a mixed model analysis: 1. Identify desired fixed-effects structure 2. Identify random-effects grouping factors 3. Identify *maximal random-effects structure justified by the design*: - Which factors/terms vary within levels of (i.e. are crossed with) each random-effects grouping factor? - Are there replicates within factor levels (or parameters/coefficients) for levels of random-effects grouping factor? 4. Choose method for calculating *p*-values and fit maximal model 5. In case of singular fits: Iteratively reduce random-effects structure until all degenerate random-effects parameters are removed/fit is not singular. --- # Mixed Models - Modern class of statistical models that extend regular regression models - Implement *partial pooling* via random-effects parameters - Random-effects parameters can account for dependencies among related data points -- .pull-left[ ### Fixed Effects - Overall or *population-level average* effect of specific model term (i.e., main effect, interaction, parameter) on dependent variable - Independent of stochastic variability controlled for by random effects - Hypothesis tests on fixed effect interpreted as hypothesis tests for terms in standard ANOVA or regression model - Possible to test specific hypotheses among factor levels (e.g., planned contrasts) ] .pull-right[ ### Random Effects - *Random-effects grouping factors*: Categorical variables that capture random or stochastic variability (e.g., participants, items, groups, or other hierarchical-structures). - In experimental settings, random effects grouping factors often part of design one wants to generalize over. - Random effects factor out idiosyncrasies of sample, thereby providing a more general estimate of the fixed effects of interest. - *Random-effects parameters*: Provide each level of random-effects grouping factor with idiosyncratic parameter set. ] --- class: inline-grey, small ### Mixed Models Formulas with `lme4`/`afex` - Full mixed model is specified in one formula. For example: `dv ~ fixed + (random|id)` - Random effects are inside parentheses with a `|`: - random-effects parameters left of `|` - random-effects grouping factor is right of `|` - Fixed effects are usually outside parentheses | Formula | Interpretation | | ------------------------|----------------------------------| | <code>(1|s)</code> | random intercepts for `s` (i.e., by-`s` random intercepts) | | <code>(1|s)+(1|i)</code> | by-`s` and by-`i` (i.e., crossed) random intercepts | | <code>(a|s)</code> or <code>(1+a|s)</code> | by-`s` random intercepts and by-`s` random slopes for `a` plus their correlation| | <code>(a*b|s)</code> | by-`s` random intercepts and by-`s` random slopes for `a`, `b`, and the `a:b` interaction plus correlations among the by-`s` random effects parameters | | <code>(0+a|s)</code> | by-`s` random slopes for `a` and no random intercept | | <code>(a||s)</code> | by-`s` random intercepts and by-`s` random slopes for `a`, but no correlation (expands to: <code>(0+a|s) + (1|s)</code>) | *Note*: Suppressing correlation parameters via `||` works only for numerical variables in `lmer` and not for factors. In `afex::mixed` it works if `expand_re = TRUE`. --- class: small # Example Data  --- class: small, inline-grey ### Skovgaard-Olsen et al. (2016) - Conditional = *if-then* statement; e.g., If global warning continues, London will be flooded. - Bayesian reasoning often assumes 'the Equation': *P*(if *A* then *B*) = *P*(*B*|*A*) - Our question: Does 'the Equation' hold? - Participants provide idiosyncratic estimates of both *P*(if *A* then *B*) and *P*(*B*|*A*). - ~100 participants recruited via `crowdflower.com` worked on 12 items: > Sophia's scenario: Sophia wishes to find a nice present for her 13-year-old son, Tim, for Christmas. She is running on a tight budget, but she knows that Tim loves participating in live role-playing in the forest and she is really skilled at sewing the orc costumes he needs. Unfortunately, she will not be able to afford the leather parts that such costumes usually have, but she will still be able to make them look nice. -- (1) *P*(*B*|*A*) (`B_given_A`): > Suppose Sophia makes Tim an orc costume. > Under this assumption, how probable is it that the following sentence is true: > Tim will be excited about his present. -- (2) *P*(if *A* then *B*) (`if_A_then_B`): > Could you please rate the probability that the following sentence is true: > IF Sophia makes Tim an orc costume, THEN he will be excited about his present. --- class: small .pull-left[ ### Skovgaard-Olsen et al. (2016) - Does 'the Equation' (i.e., *P*(if *A* then *B*) = *P*(*B*|*A*)) hold? - Participants provided idiosyncratic estimates of *P*(if *A* then *B*) (`if_A_then_B`) and *P*(*B*|*A*) (`B_given_A`) for each item. - Each participant worked on 12 items. ```r # Session -> Set Working Directory -> # -> To Source File Location load("ssk16_dat_prepared_ex2.rda") # full data: https://osf.io/j4swp/ str(dat2, width=50, strict.width = "cut") ``` ``` ## 'data.frame': 752 obs. of 7 variables: ## $ p_id : Factor w/ 94 levels "102_P(if".. ## $ i_id : Factor w/ 12 levels "1","2","".. ## $ B_given_A : num 52 60 79 0 51 79 80 77 98.. ## $ B_given_A_c : num 0.02 0.1 0.29 -0.5 0.01 0.. ## $ if_A_then_B : num 52 1 84 0 51 94 1 81 95 9.. ## $ if_A_then_B_c: num 0.02 -0.49 0.34 -0.5 0.01.. ## $ rel_cond : Factor w/ 2 levels "PO","IR": .. ``` ] .pull-right[ ```r library("tidyverse") theme_set(theme_bw(base_size = 17)) ggplot(data = dat2) + geom_point(mapping = aes(x = B_given_A, y = if_A_then_B), alpha = 0.2, pch = 16, size = 3) + coord_fixed() ``` <!-- --> ] --- class:small # Example Data: Skovgaard-Olsen et al. (2016) - Is there an overall association between *P*(if *A* then *B*) and *P*(*B*|*A*)? - For technical reason, we work with scaled variables (i.e., `\((x-50)/100\)`). `lme4` works better with variables near -1 to 1. .pull-left[ ```r m_fixed <- lm(if_A_then_B_c ~ B_given_A_c, dat2) summary(m_fixed) ``` ``` ## ## Call: ## lm(formula = if_A_then_B_c ~ B_given_A_c, data = dat2) ## ## Residuals: ## Min 1Q Median 3Q Max ## -0.8014 -0.0776 0.0605 0.1886 0.9224 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) -0.0605 0.0106 -5.7 1.8e-08 *** ## B_given_A_c 0.7238 0.0287 25.2 < 2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 0.287 on 750 degrees of freedom ## Multiple R-squared: 0.458, Adjusted R-squared: 0.457 ## F-statistic: 634 on 1 and 750 DF, p-value: <2e-16 ``` ] .pull-right[ <!-- --> `$$y=\beta_0 + \beta_{B|A}X_{B|A} + \epsilon$$` ] --- class: small .pull-left2[ ### Fixed Effects Model `$$y=\beta_0 + \beta_{B|A}X_{B|A} + \epsilon$$` - `\(\beta\)` are scalar regression parameters - `\(X\)` is a covariate vector (numerical independent variable) - assumes error vector `\(\epsilon\)` is *iid*, `\(\epsilon \sim \mathcal{N}(0, \sigma^2_{\epsilon})\)`, which is likely false. ] .pull-right2[ <!-- --> ] -- ### A First Mixed Effects Model `$$y=\beta_0 + (\beta_{B|A}+ S_{B|A})X_{B|A} + \epsilon$$` - `\(S_{B|A}\)` is a zero-centered vector of participant specific random effects: `\(S_{B|A} \sim \mathcal{N}(0, \sigma^2_{S_{B|A}})\)` - `\(S_{B|A}\)` provides each participant with their own regression weight: overall `\(\beta_{B|A}\)` plus idiosyncratic `\(S_{B|A}\)`. - As parameter, model estimates variance of random effects vector, `\(\sigma^2_{S_{B|A}}\)`. - As `\(S_{B|A}\)` alters the regression slope `\(\beta_{B|A}\)`, also known as *random slope*. - In `lme4::lmer` syntax: `lmer(if_A_then_B ~ B_given_A + (0+B_given_A|p_id), dat2)` --- class: small .pull-left2[ ### Fixed Effects Model `$$y=\beta_0 + \beta_{B|A}X_{B|A} + \epsilon$$` - `\(\beta\)` are scalar regression parameters - `\(X\)` is a covariate vector (numerical independent variable) - assumes error vector `\(\epsilon\)` is *iid*, `\(\epsilon \sim \mathcal{N}(0, \sigma^2_{\epsilon})\)`, which is likely false. ] .pull-right2[ <!-- --> ] ### A First Mixed Effects Model `$$y=\beta_0 + (\beta_{B|A}+ S_{B|A})X_{B|A} + \epsilon$$` - `\(S_{B|A}\)` is a zero-centered vector of participant specific random effects: `\(S_{B|A} \sim \mathcal{N}(0, \sigma^2_{S_{B|A}})\)` - `\(S_{B|A}\)` provides each participant with their own regression weight: overall `\(\beta_{B|A}\)` plus idiosyncratic `\(S_{B|A}\)`. - As parameter, model estimates variance of random effects vector, `\(\sigma^2_{S_{B|A}}\)`. - As `\(S_{B|A}\)` alters the regression slope `\(\beta_{B|A}\)`, also known as *random slope*. - In `lme4::lmer` syntax: `lmer(if_A_then_B ~ B_given_A + (0+B_given_A|p_id), dat2)` --- class: small ### A More Reasonable Mixed Model First model did not allow for different intercepts, `\(\beta_0\)`, for each participant. `$$y=\beta_0 + S_0 + (\beta_{B|A}+ S_{B|A})X_{B|A} + \epsilon$$` - Model now has a random intercept, `\(S_0\)`, and a random slope, `\(S_{B|A}\)`. - `\(S\)`-vectors still zero-centered vectors of participant specific random effects. However, we now estimate both, variance and covariance of random effects: `$$\left( \begin{matrix} S_0 \\ S_{B|A} \end{matrix} \right) \sim \mathcal{N}\left( \left[ \begin{matrix} 0 \\ 0 \end{matrix} \right] , \left[ \begin{matrix} \sigma^2_{S_0}&\rho_{S_{0},S_{B|A}}\sigma_{S_{0}}\sigma_{S_{B|A}} \\ \rho_{S_{B|A},S_{0}}\sigma_{S_{0}}\sigma_{S_{B|A}}&\sigma^2_{S_{B|A}} \end{matrix} \right] \right)$$` Each `\(S_i\)` idiosyncratic intercept & slope: `lmer(if_A_then_B_c ~ B_given_A_c + (B_given_A_c|p_id), dat2)` ``` ## boundary (singular) fit: see ?isSingular ``` <img src="mixed_models_files/figure-html/unnamed-chunk-7-1.png" width="20%" /> --- ### Interim Summary I *Fixed-effects parameters*: Overall effect of specific model term on dependent variable -- *Random-effects parameters*: - zero-centered offsets/displacements for each level of random-effects grouping factor - added to specific fixed-effects parameter - assumed to follow normal distribution which provides hierarchical shrinkage, thereby avoiding over-fitting - should be added to each parameter that varies within the levels of a random-effects grouping factor (i.e., factor is *crossed* with random-effects grouping factor) <img src="mixed_models_files/figure-html/unnamed-chunk-8-1.png" width="25%" /> --- class: small ```r library("lme4") m_r <- lmer(if_A_then_B_c ~ B_given_A_c + (1+B_given_A_c|p_id), dat2) ``` ``` ## boundary (singular) fit: see ?isSingular ``` ```r summary(m_r) ``` ``` ## Linear mixed model fit by REML ['lmerMod'] ## Formula: if_A_then_B_c ~ B_given_A_c + (1 + B_given_A_c | p_id) ## Data: dat2 ## ## REML criterion at convergence: 265.1 ## ## Scaled residuals: ## Min 1Q Median 3Q Max ## -2.841 -0.309 0.217 0.602 3.208 ## ## Random effects: ## Groups Name Variance Std.Dev. Corr ## p_id (Intercept) 0.0000 0.000 ## B_given_A_c 0.0159 0.126 NaN ## Residual 0.0802 0.283 ## Number of obs: 752, groups: p_id, 94 ## ## Fixed effects: ## Estimate Std. Error t value ## (Intercept) -0.0614 0.0106 -5.8 ## B_given_A_c 0.7275 0.0315 23.1 ## ## Correlation of Fixed Effects: ## (Intr) ## B_given_A_c -0.158 ## convergence code: 0 ## boundary (singular) fit: see ?isSingular ``` --- # Exercise 2.1: Fitting First Mixed Model - Open `exercises/exercise_2.1.Rmd` or see corresponding handout. - **Task 1:** Goal is to recreate the first two models from the slides, add one more model, and inspect the results. - Dependent variable: `if_A_then_B_c` - Fixed effect: `B_given_A_c` 1. The first model only has by-participant (i.e., by `p_id`) random-slopes for `B_given_A_c`. 2. The second model has has by-participant random-slopes for `B_given_A_c` and random-intercepts, as well as the correlation between the random-effects parameters. 3. The third (and new) model only has by-participant random intercepts and no random slopes. - Which model shows a singular fit or other convergence problems? Do you have an idea where the convergence problems come from? - What do the parameter estimates of the random effects mean? - Does the choice of random-effects structure affect the fixed-effect estimates and/or inferential statistics? - Which model do you think would be the best to report? - **Task 2**: Suppressing the Correlation. The only model we have not yet considered for this data is a model without correlation among the random-effects parameters. Can you set it up? --- class: small ### Example Data Extended: Skovgaard-Olsen et al. (2016) - Conditional = *if-then* statement; e.g., If global warning continues, London will be flooded. - Bayesian reasoning often assumes 'the Equation': *P*(if *A* then *B*) = *P*(*B*|*A*) - Our question: Does the Equation hold even if no apparent relationship between *A* and *B*? - positive relevance (PO): *A* is a reason for *B* - irrelevance (IR): *A* and *B* have no apparent relationship -- > Sophia's scenario: Sophia wishes to find a nice present for her 13-year-old son, Tim, for Christmas. She is running on a tight budget, but she knows that Tim loves participating in live role-playing in the forest and she is really skilled at sewing the orc costumes he needs. Unfortunately, she will not be able to afford the leather parts that such costumes usually have, but she will still be able to make them look nice. -- ### Positive relevance (PO) > IF Sophia makes Tim an orc costume, THEN he will be excited about his present. -- ### Irrelevance (IR) > IF Sophia regularly wears shoes, THEN Tim will be excited about his present. --- # Example Data: Skovgaard-Olsen et al. (2016) <img src="mixed_models_files/figure-html/unnamed-chunk-10-1.png" width="80%" /> --- class: small .pull-left[ ### Fixed Effects Model ```r afex::set_sum_contrasts() m_fixed <- lm(if_A_then_B_c ~ B_given_A_c*rel_cond, dat2) summary(m_fixed) ``` ``` ## ## Call: ## lm(formula = if_A_then_B_c ~ B_given_A_c * rel_cond, data = dat2) ## ## Residuals: ## Min 1Q Median 3Q Max ## -0.6951 -0.0914 -0.0090 0.0611 0.8155 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) -0.06965 0.00902 -7.72 3.8e-14 *** ## B_given_A_c 0.62031 0.02441 25.41 < 2e-16 *** ## rel_cond1 0.14790 0.00902 16.39 < 2e-16 *** ## B_given_A_c:rel_cond1 0.16725 0.02441 6.85 1.5e-11 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 0.235 on 748 degrees of freedom ## Multiple R-squared: 0.637, Adjusted R-squared: 0.635 ## F-statistic: 437 on 3 and 748 DF, p-value: <2e-16 ``` ] .pull-right[ <!-- --> `$$y=\beta_0 + \beta_{B|A}X_{B|A} + \beta_{r}X_{r} + \beta_{I}X_{I} + \epsilon$$` ] --- class: small .pull-left[ ### Fixed Effects Model `$$y=\beta_0 + \beta_{B|A}X_{B|A} + \beta_{r}X_{r} + \beta_{I}X_{I} + \epsilon$$` - `\(\beta\)` are scalar regression parameters - `\(X\)` are covariate vectors (numerical independent variables with -1 and 1 for factors) - assumes error vector `\(\epsilon\)` is *iid*, `\(\epsilon \sim \mathcal{N}(0, \sigma^2_{\epsilon})\)`, which is likely false. ] .pull-right[ <!-- --> ] -- ### A First Mixed Effects Model `$$y=\beta_0 + (\beta_{B|A}+ S_{B|A})X_{B|A} + \beta_{r}X_{r} + \beta_{I}X_{I} + \epsilon$$` - `\(S_{B|A}\)` is a zero-centered vector of participant specific random effects: `\(S_{B|A} \sim \mathcal{N}(0, \sigma^2_{S_{B|A}})\)` - `\(S_{B|A}\)` provides each participant with their own regression weight: overall `\(\beta_{B|A}\)` plus idiosyncratic `\(S_{B|A}\)`. - As parameter, model estimates variance of random effects vector, `\(\sigma^2_{S_{B|A}}\)`. - As `\(S_{B|A}\)` alters the regression slope `\(\beta_{B|A}\)`, also known as *random slope*. - In `lme4::lmer` syntax: `lmer(if_A_then_B ~ B_given_A*rel_cond + (0+B_given_A|p_id), dat2)` --- class: small .pull-left[ ### Fixed Effects Model `$$y=\beta_0 + \beta_{B|A}X_{B|A} + \beta_{r}X_{r} + \beta_{I}X_{I} + \epsilon$$` - `\(\beta\)` are scalar regression parameters - `\(X\)` are covariate vectors (numerical independent variables with -1 and 1 for factors) - assumes error vector `\(\epsilon\)` is *iid*, `\(\epsilon \sim \mathcal{N}(0, \sigma^2_{\epsilon})\)`, which is likely false. ] .pull-right[ <!-- --> ] ### A First Mixed Effects Model `$$y=\beta_0 + (\beta_{B|A}+ S_{B|A})X_{B|A} + \beta_{r}X_{r} + \beta_{I}X_{I} + \epsilon$$` - `\(S_{B|A}\)` is a zero-centered vector of participant specific random effects: `\(S_{B|A} \sim \mathcal{N}(0, \sigma^2_{S_{B|A}})\)` - `\(S_{B|A}\)` provides each participant with their own regression weight: overall `\(\beta_{B|A}\)` plus idiosyncratic `\(S_{B|A}\)`. - As parameter, model estimates variance of random effects vector, `\(\sigma^2_{S_{B|A}}\)`. - As `\(S_{B|A}\)` alters the regression slope `\(\beta_{B|A}\)`, also known as *random slope*. - In `lme4::lmer` syntax: `lmer(if_A_then_B ~ B_given_A*rel_cond + (0+B_given_A|p_id), dat2)` --- class: small ### A More Reasonable Mixed Model First model did not allow for different intercepts, `\(\beta_0\)`, for each participant. `$$y=\beta_0 + S_0 + (\beta_{B|A}+ S_{B|A})X_{B|A} + \beta_{r}X_{r} + \beta_{I}X_{I} + \epsilon$$` - Model now has a random intercept, `\(S_0\)`, and a random slope, `\(S_{B|A}\)`. - `\(S\)`-vectors still zero-centered vectors of participant specific random effects. However, we now estimate both, variance and covariance of random effects: `$$\left( \begin{matrix} S_0 \\ S_{B|A} \end{matrix} \right) \sim \mathcal{N}\left( \left[ \begin{matrix} 0 \\ 0 \end{matrix} \right] , \left[ \begin{matrix} \sigma^2_{S_0}&\rho_{S_{0},S_{B|A}}\sigma_{S_{0}}\sigma_{S_{B|A}} \\ \rho_{S_{B|A},S_{0}}\sigma_{S_{0}}\sigma_{S_{B|A}}&\sigma^2_{S_{B|A}} \end{matrix} \right] \right)$$` Each `\(S_i\)` idiosyncratic intercept & slope: `lmer(if_A_then_B ~ B_given_A*rel_cond + (B_given_A|p_id), dat2)` .pull-left[ 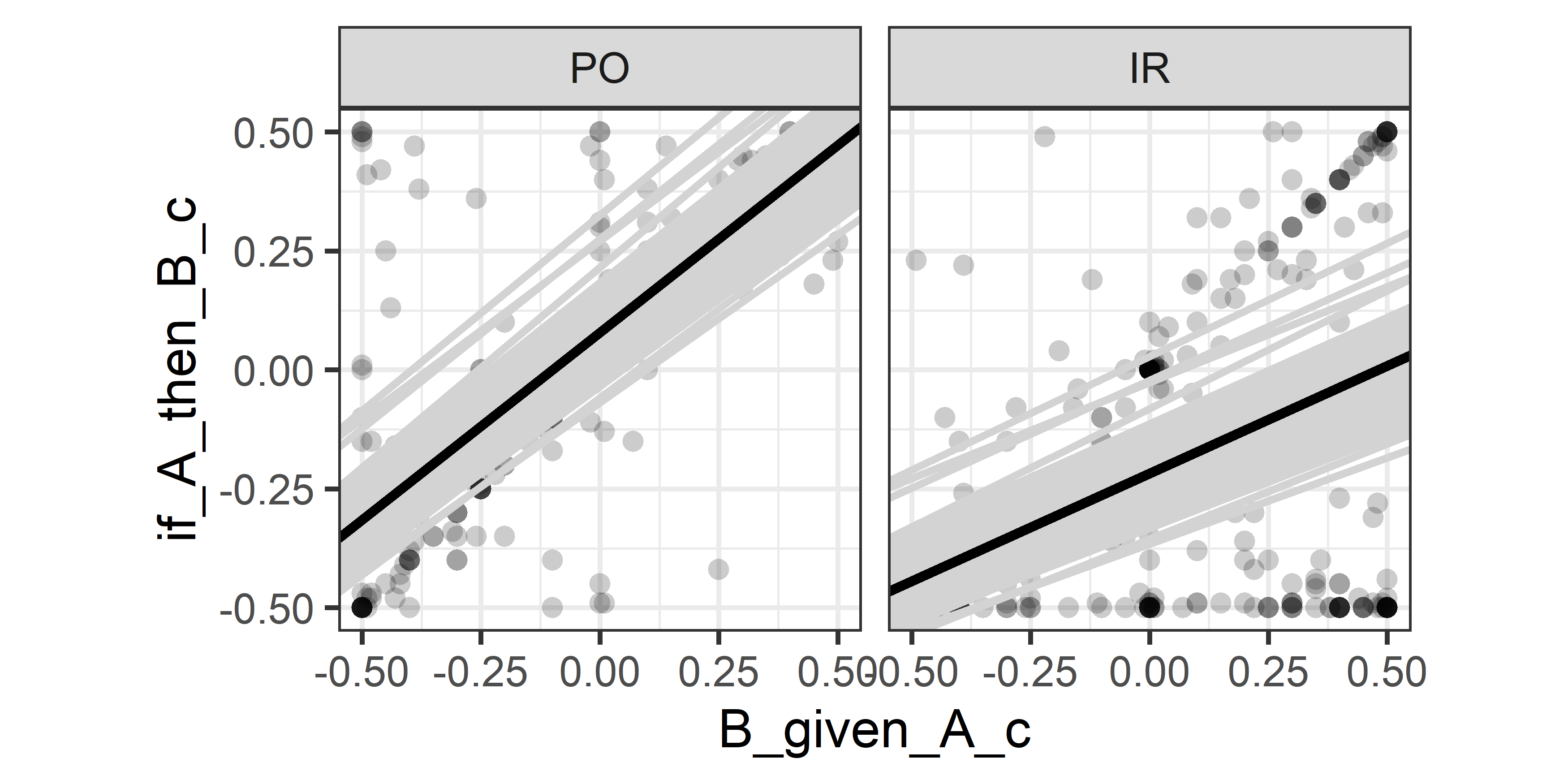<!-- --> ] --- class: small ### Maximal By-Participant Mixed Model `$$y=\beta_0 + S_0 + (\beta_{B|A}+ S_{B|A})X_{B|A} + (\beta_{r}+ S_{r})X_{r} + (\beta_{I}+ S_{I})X_{I} + \epsilon$$` - Model estimates 4 variances for zero-centered `\(S\)` vectors, 1 residual variance, and 6 correlations among random effects. -- .pull-left[ ```r library("lme4") m_p_max <- lmer(if_A_then_B_c ~ B_given_A_c*rel_cond + (B_given_A_c*rel_cond|p_id), dat2) summary(m_p_max)$varcor ``` ``` ## Groups Name Std.Dev. Corr ## p_id (Intercept) 0.122 ## B_given_A_c 0.229 0.14 ## rel_cond1 0.100 -0.43 -0.96 ## B_given_A_c:rel_cond1 0.229 -1.00 -0.14 0.43 ## Residual 0.154 ``` ```r summary(m_p_max)$coefficients ``` ``` ## Estimate Std. Error t value ## (Intercept) -0.07923 0.01427 -5.554 ## B_given_A_c 0.63015 0.03007 20.957 ## rel_cond1 0.15045 0.01228 12.247 ## B_given_A_c:rel_cond1 0.17898 0.02985 5.996 ``` ] .pull-right[ 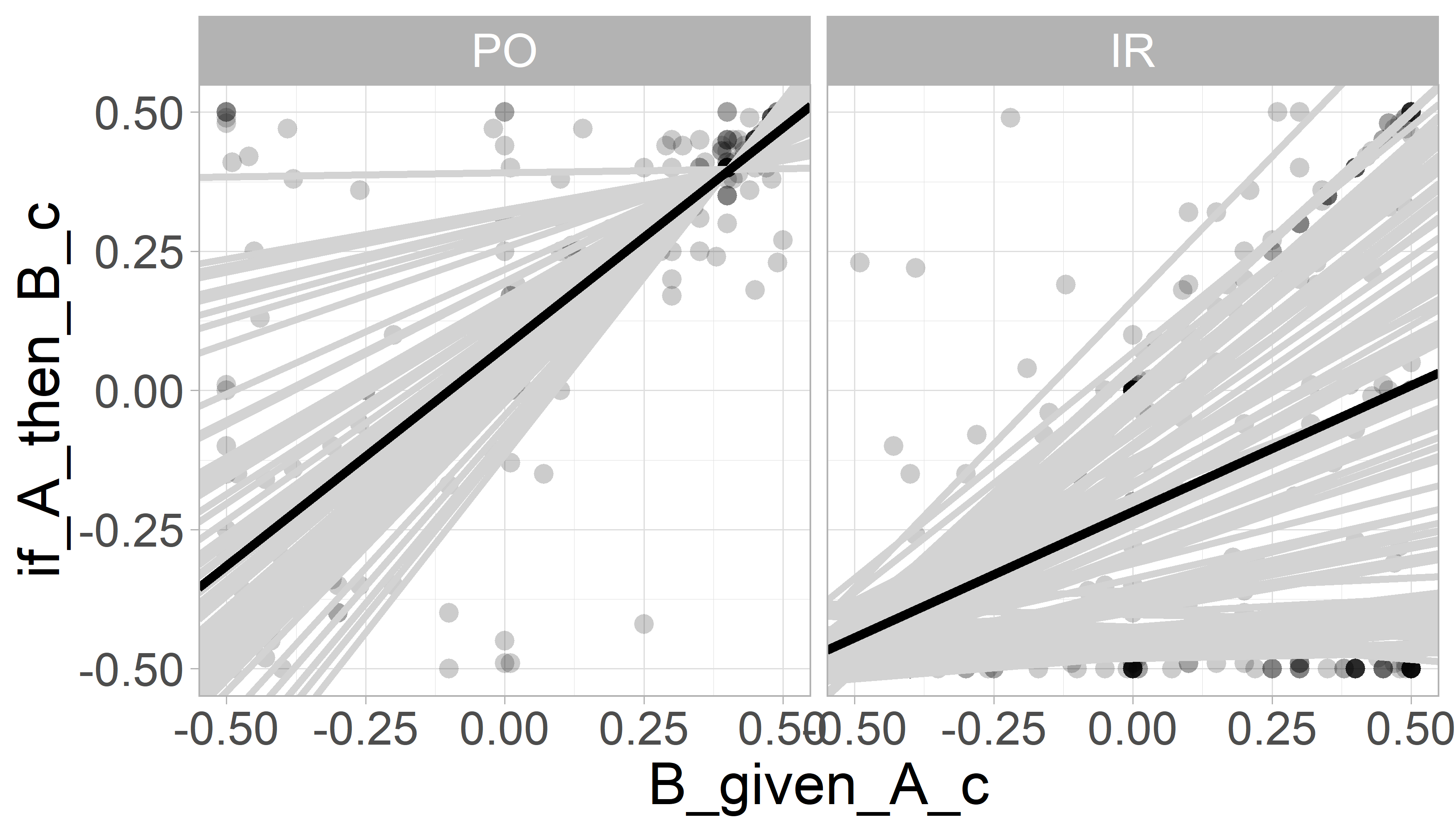<!-- --> ] --- class: small ## Crossed Random-Effects So far only considered *participant* as random-effects grouping factor: - Each participant provides several responses: Random intercept allows idiosyncratic intercept. - `B_given_A` and `rel_cond` are within-subjects variables: Random slopes allow idiosyncratic effects. Participant is only one source of stochastic variability. We usually want to generalize over both *participants* and *items*. - Example data: Each participant provides 1 response for each of 12 items with condition randomly selected. - All factors also vary within-items. Mixed models allow multiple independent random effects (where `\(I\)` are vectors of item-specific offsets): `$$y=\beta_0 + S_0 + I_0 + (\beta_{B|A} + S_{B|A} + I_{B|A})X_{B|A} + (\beta_{r} + S_{r}+ I_{r})X_{r} + (\beta_{I}+ S_{I}+ I_{I})X_{I} + \epsilon$$` ```r m_max <- lmer(if_A_then_B_c ~ B_given_A_c*rel_cond + (B_given_A_c*rel_cond|p_id) + (B_given_A_c*rel_cond|i_id), dat2) ``` ``` ## boundary (singular) fit: see ?isSingular ``` --- class: small ```r summary(m_max) ``` ``` ## Linear mixed model fit by REML ['lmerMod'] ## Formula: if_A_then_B_c ~ B_given_A_c * rel_cond + (B_given_A_c * rel_cond | ## p_id) + (B_given_A_c * rel_cond | i_id) ## Data: dat2 ## ## REML criterion at convergence: -387.9 ## ## Scaled residuals: ## Min 1Q Median 3Q Max ## -5.112 -0.325 0.015 0.259 3.739 ## ## Random effects: ## Groups Name Variance Std.Dev. Corr ## p_id (Intercept) 0.01623 0.1274 ## B_given_A_c 0.05380 0.2320 0.14 ## rel_cond1 0.01021 0.1011 -0.44 -0.95 ## B_given_A_c:rel_cond1 0.05683 0.2384 -1.00 -0.16 0.46 ## i_id (Intercept) 0.00116 0.0340 ## B_given_A_c 0.00926 0.0962 0.14 ## rel_cond1 0.00175 0.0418 -0.12 -1.00 ## B_given_A_c:rel_cond1 0.00349 0.0591 -1.00 -0.12 0.10 ## Residual 0.02096 0.1448 ## Number of obs: 752, groups: p_id, 94; i_id, 12 ## ## Fixed effects: ## Estimate Std. Error t value ## (Intercept) -0.0765 0.0177 -4.32 ## B_given_A_c 0.6262 0.0410 15.26 ## rel_cond1 0.1535 0.0173 8.90 ## B_given_A_c:rel_cond1 0.1681 0.0350 4.81 ## ## Correlation of Fixed Effects: ## (Intr) B_g_A_ rl_cn1 ## B_given_A_c 0.083 ## rel_cond1 -0.223 -0.887 ## B_gvn_A_:_1 -0.881 -0.093 0.192 ## convergence code: 0 ## boundary (singular) fit: see ?isSingular ``` --- class:small ### Effect of Partial-Pooling / Hierarchical Shrinkage / Regularization .pull-left[ Comparison of no-pooling and partial-pooling (i.e., LMM) estimates for `B_given_A` slopes: <img src="mixed_models_files/figure-html/unnamed-chunk-21-1.png" width="500px" height="300px" /> ] .pull-right[ Distribution of no-pooling and partial-pooling (i.e., LMM) estimates for `B_given_A` slopes: <img src="mixed_models_files/figure-html/unnamed-chunk-22-1.png" width="400px" height="350px" /> ] - If individual effects can be assumed to come from one normal distribution, partial-pooling provides better estimates than no-pooling even on the individual level (at least on average). - a.k.a. *James-Stein Estimation* (e.g., Efron & Hastie, 2016, ch. 7) or *Stein's phenomenon*, more generally *regularization*: *ridge regression*, *lasso*, *penalized least squares*, *penalized likelihood*, ... --- class:small <img src="mixed_models_files/figure-html/unnamed-chunk-23-1.png" width="1000px" height="500px" /> - from Tristan Mahr: https://tjmahr.github.io/plotting-partial-pooling-in-mixed-effects-models/ --- class: small ### Types of Random Effects  --- class: small, inline-grey ### Crossed Versus Nested - Factor `A` is **crossed** with factor `B` if multiple levels of `A` appear within multiple levels of `B`. Note that this definition allows for missing values (i.e., it does not need to hold that all levels of `A` appear in all levels of `B`). For example: - Levels `a1`, `a2`, ... of `A` appear in `b1` of `B` and in `b2` of `B`, etc. - A within-subject factor (e.g., `congruency`) is crossed with participants. - If each participant responds to a random subset of items and each item is responded to by several participants, `participant` and `item` are crossed. - Factor `A` is **nested** within factor `B` if some levels of `A` appear only within specific levels of factor `B`. E.g.: - Levels `a1`, `a2`, and `a3` of `A` appear only in `b1` of `B` and `a4`, `a5`, and `a6` of `A` appear only in `b2` of `B` ... - If student can be member of one class only and several classes were observed, factor `student` is nested within factor `class`. - Both dependency structures dealt with in same conceptual manner, via independent random effects-parameters. Specifically, both need independent random effects terms in model formula. For example: - For `students` nested within `class`, where each student has unique label (i.e., `student` id 1 is assigned to exactly one student and not to different students in different classes), at least: `... + (1|student) + (1|class)` - If additional factor `A` is crossed with `class`, but not with `student` (e.g., some students in each class receive treatment `a1`, some others `a2`), by-class random slopes need to be added: `... + (1|student) + (A|class)` --- ### Interim Summary II *Fixed-effects parameters*: Overall (or population-average) effect of specific model term on dependent variable *Random-effects parameters*: - zero-centered offsets/displacements for each level of random-effects grouping factor - added to specific fixed-effects parameter (can also be added in absence of corresponding fixed-effects parameter) - called *random-intercept* if added to the intercept, and *random-slope* if added to any other parameter. - assumed to follow normal distribution which provides hierarchical shrinkage, thereby avoiding overfitting - should be added to each parameter that varies within the levels of a random-effects grouping factor (i.e., factor is *crossed* with random-effects grouping factor) - Note: random-slopes can only be added if there exist multiple data points (i.e., replications) for each level of random-effects grouping factor and each parameter (e.g., each cell of corresponding factor or design-cell) (e.g., http://singmann.org/mixed-models-for-anova-designs-with-one-observation-per-unit-of-observation-and-cell-of-the-design/) - mixed model can have random-effects for multiple random-effects grouping factor (e.g., factors one wants to generalize over) - whether data has only a single random-effects grouping factor, crossed random-effects grouping factors, or nested random-effects grouping factors, random-effects parameters is only mechanism for handling dependencies in mixed models --- class: center, middle, inverse # Exercise 2.2: Pooling Revisited (see `exercises\exercise_2.2_PP.Rmd` in folder or handout) --- class: center, middle, inverse # Practical Issues with Mixed Models in `R` --- class: small # Hypothesis-Tests for Mixed Models `lme4::lmer` does not include *p*-values. -- `afex::mixed` provides four different methods: 1. Kenward-Roger (`method="KR"`, default): Provides best-protection against anti-conservative results, requires a lot of RAM for complicated random-effects structures. 2. Satterthwaite (`method="S"`): Similar to KR, but requires less RAM. 3. Parametric-bootstrap (`method="PB"`): Simulation-based, can take a lot of time (can be speed-up using parallel computation). 4. Likelihood-ratio tests (`method="LRT"`): Provides worst control for anti-conservative results. Can be used if all else fails or if all random effects grouping factors have large numbers of levels (e.g., over 50). Methods do not differ for example data: ```r library("afex") mixed(if_A_then_B_c ~ B_given_A_c*rel_cond + (B_given_A_c*rel_cond|p_id), dat2, dat2, method = "KR") mixed(if_A_then_B_c ~ B_given_A_c*rel_cond + (B_given_A_c*rel_cond|p_id), dat2, dat2, method = "S") mixed(if_A_then_B_c ~ B_given_A_c*rel_cond + (B_given_A_c*rel_cond|p_id), dat2, method = "LRT") # mixed(if_A_then_B_c ~ B_given_A_c*rel_cond + (B_given_A_c*rel_cond|p_id), dat2, method = "PB") ``` --- class:small # Specifying Random-Effects Structure - Omitting random-effects parameters for model terms which vary within the levels of a random-effects grouping factor and for which random variability exists leads to non-iid residuals (i.e., `\(\epsilon\)`) and potentially anti-conservative results (e.g., Barr, Levy, Scheepers, & Tily, 2013). -- - Safeguard is **maximal model justified by the design** (Barr et al., 2013). - Which factors/terms vary within levels of (i.e. are crossed with) each random-effects grouping factor? - Are there replicates within factor levels (or parameters/coefficients) for levels of random-effects grouping factor? -- - If maximal model is overparameterized and/or contains degenerate estimates or singular fits (can be indicated by convergence warnings/messages), power of maximal model can be reduced and a reduced model should be used (Bates et al., 2015; Matuschek et al., 2017). - Start by removing correlation among random-effects parameters - Remove random-effects parameters with variance of 0 and/or for highest-order effects with lowest variance - It can sometimes help to try different optimizers (in `afex::mixed` `all_fit = TRUE`) - Compare *p*-values/fixed-effects estimates across models (*p*-values from degenerate/minimal models are not reliable) - **Warning:** Reducing model introduces unknown risk of anti-conservativity, and should be done with caution! --- # High-Level Overview Steps for running a mixed model analysis: 1. Identify desired fixed-effects structure 2. Identify random-effects grouping factors 3. Identify *maximal random-effects structure justified by the design*: - Which factors/terms vary within levels of (i.e. are crossed with) each random-effects grouping factor? - Are there replicates within factor levels (or parameters/coefficients) for levels of random-effects grouping factor? 4. Choose method for calculating *p*-values and fit maximal model 5. In case of singular fits: Iteratively reduce random-effects structure until all degenerate random-effects parameters are removed/fit is not singular. --- class: small ### Suppressing Correlations Among Random Effects .pull-left[ - `lmer` allows suppressing correlation among random effects using `||` syntax. However, **only for numerical variables.** - `afex::mixed()` allows using `||` also for factors if `expand_re = TRUE`: ```r m_red <- mixed( if_A_then_B_c ~ B_given_A_c*rel_cond + (B_given_A_c*rel_cond||p_id), dat2, method = "S", expand_re = TRUE) ``` ```r summary(m_red)$varcor ``` ``` ## Groups Name Std.Dev. ## p_id (Intercept) 0.1102 ## p_id.1 re1.B_given_A_c 0.1757 ## p_id.2 re1.rel_cond1 0.0842 ## p_id.3 re1.B_given_A_c_by_rel_cond1 0.1939 ## Residual 0.1723 ``` ] .pull-right[ ```r m_red ``` ``` ## Mixed Model Anova Table (Type 3 tests, S-method) ## ## Model: if_A_then_B_c ~ B_given_A_c * rel_cond + (B_given_A_c * rel_cond || ## Model: p_id) ## Data: dat2 ## Effect df F p.value ## 1 B_given_A_c 1, 89.03 484.39 *** <.0001 ## 2 rel_cond 1, 89.44 174.43 *** <.0001 ## 3 B_given_A_c:rel_cond 1, 85.45 42.24 *** <.0001 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '+' 0.1 ' ' 1 ``` 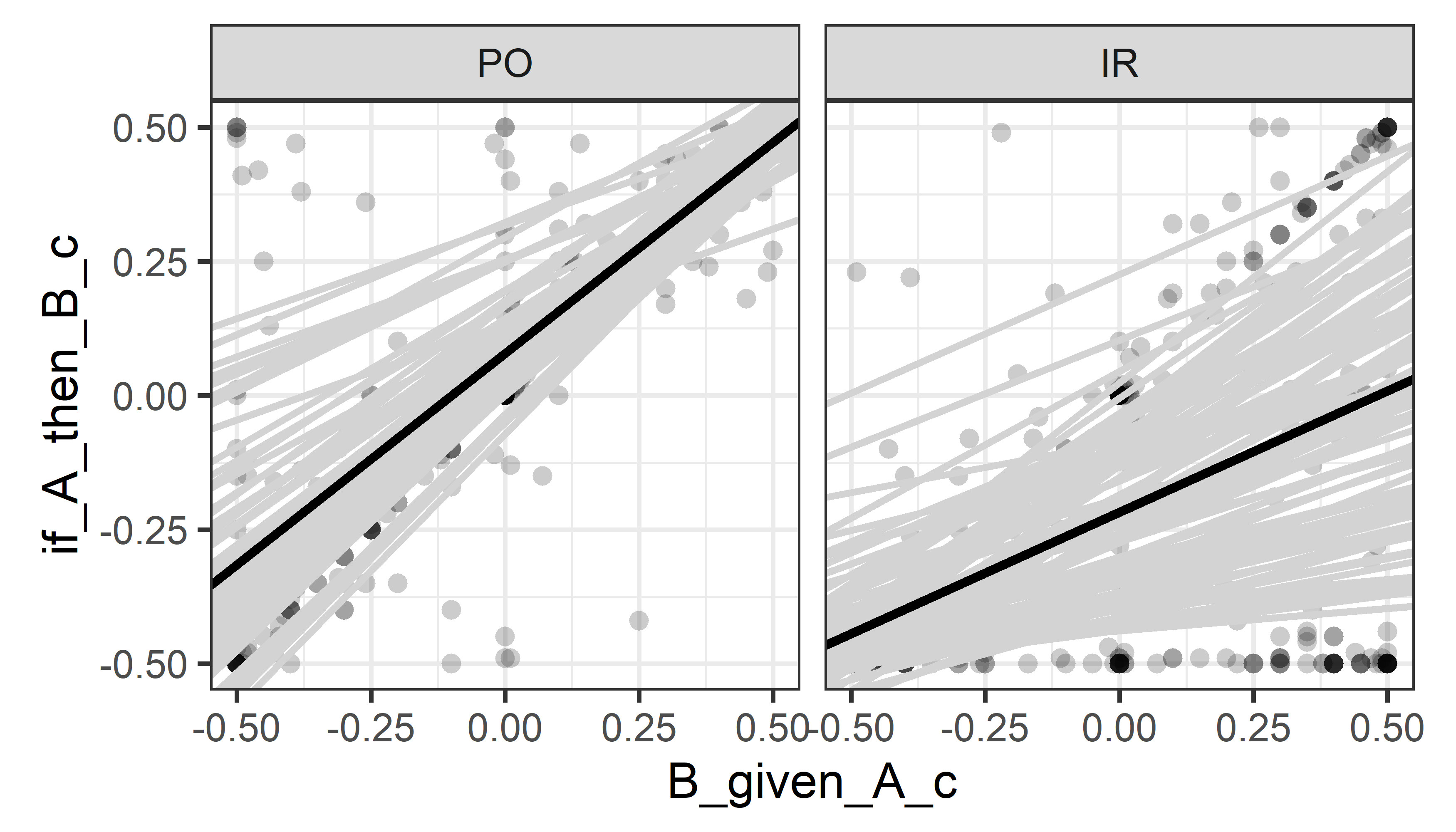<!-- --> ] --- ## Using `afex` I ```r library("afex") ma_1 <- mixed(if_A_then_B_c ~ B_given_A_c*rel_cond + (B_given_A_c*rel_cond|p_id) + (B_given_A_c*rel_cond|i_id), dat2, method = "S") ``` ``` ## Numerical variables NOT centered on 0: B_given_A_c ## If in interactions, interpretation of lower order (e.g., main) effects difficult. ``` ``` ## Fitting one lmer() model. ``` ``` ## boundary (singular) fit: see ?isSingular ``` ``` ## [DONE] ## Calculating p-values. [DONE] ``` -- ```r ma_2 <- mixed(if_A_then_B_c ~ B_given_A_c*rel_cond + (B_given_A_c*rel_cond||p_id) + (B_given_A_c*rel_cond||i_id), dat2, method = "S", expand_re = TRUE) ``` ``` ## Numerical variables NOT centered on 0: B_given_A_c ## If in interactions, interpretation of lower order (e.g., main) effects difficult. ``` ``` ## Fitting one lmer() model. ``` ``` ## boundary (singular) fit: see ?isSingular ``` ``` ## [DONE] ## Calculating p-values. [DONE] ``` --- ## Using `afex` II ```r summary(ma_2)$varcor ``` ``` ## Groups Name Std.Dev. ## p_id (Intercept) 0.1130 ## p_id.1 re1.B_given_A_c 0.1781 ## p_id.2 re1.rel_cond1 0.0843 ## p_id.3 re1.B_given_A_c_by_rel_cond1 0.1996 ## i_id (Intercept) 0.0181 ## i_id.1 re2.B_given_A_c 0.0737 ## i_id.2 re2.rel_cond1 0.0287 ## i_id.3 re2.B_given_A_c_by_rel_cond1 0.0000 ## Residual 0.1664 ``` -- ```r ma_3 <- mixed(if_A_then_B_c ~ B_given_A_c*rel_cond + (B_given_A_c*rel_cond||p_id) + (B_given_A_c+rel_cond||i_id), dat2, method = "S", expand_re = TRUE) ``` ``` ## Numerical variables NOT centered on 0: B_given_A_c ## If in interactions, interpretation of lower order (e.g., main) effects difficult. ``` ``` ## Fitting one lmer() model. [DONE] ## Calculating p-values. [DONE] ``` --- ## Using `afex`: ANOVA Table ```r ma_3 ## or: nice(ma_3) ``` ``` ## Mixed Model Anova Table (Type 3 tests, S-method) ## ## Model: if_A_then_B_c ~ B_given_A_c * rel_cond + (B_given_A_c * rel_cond || ## Model: p_id) + (B_given_A_c + rel_cond || i_id) ## Data: dat2 ## Effect df F p.value ## 1 B_given_A_c 1, 18.74 297.48 *** <.0001 ## 2 rel_cond 1, 23.46 115.17 *** <.0001 ## 3 B_given_A_c:rel_cond 1, 86.54 38.35 *** <.0001 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '+' 0.1 ' ' 1 ``` - Usually one is interested in tests of fixed effects. `afex` `print()` (or `nice()`) method presents convenient ANOVA table. -- - `summary()` returns `lme4` summary. - Other `lme4` methods can be used via accessing `model$full_model`. E.g.: `fixed(model$full_model)` --- class: small ```r summary(ma_3) ## lme4 summary() output ``` ``` ## Linear mixed model fit by REML. t-tests use Satterthwaite's method ['lmerModLmerTest'] ## Formula: if_A_then_B_c ~ B_given_A_c * rel_cond + (1 + re1.B_given_A_c + ## re1.rel_cond1 + re1.B_given_A_c_by_rel_cond1 || p_id) + (1 + ## re2.B_given_A_c + re2.rel_cond1 || i_id) ## Data: data ## ## REML criterion at convergence: -137 ## ## Scaled residuals: ## Min 1Q Median 3Q Max ## -3.616 -0.352 -0.015 0.304 3.106 ## ## Random effects: ## Groups Name Variance Std.Dev. ## p_id (Intercept) 0.012772 0.1130 ## p_id.1 re1.B_given_A_c 0.031735 0.1781 ## p_id.2 re1.rel_cond1 0.007109 0.0843 ## p_id.3 re1.B_given_A_c_by_rel_cond1 0.039839 0.1996 ## i_id (Intercept) 0.000328 0.0181 ## i_id.1 re2.B_given_A_c 0.005430 0.0737 ## i_id.2 re2.rel_cond1 0.000825 0.0287 ## Residual 0.027674 0.1664 ## Number of obs: 752, groups: p_id, 94; i_id, 12 ## ## Fixed effects: ## Estimate Std. Error df t value Pr(>|t|) ## (Intercept) -0.0728 0.0146 46.3267 -4.98 9.3e-06 *** ## B_given_A_c 0.6054 0.0351 18.7396 17.25 5.9e-13 *** ## rel_cond1 0.1498 0.0140 23.4581 10.73 1.6e-10 *** ## B_given_A_c:rel_cond1 0.1820 0.0294 86.5370 6.19 1.9e-08 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Correlation of Fixed Effects: ## (Intr) B_g_A_ rl_cn1 ## B_given_A_c -0.063 ## rel_cond1 0.026 -0.090 ## B_gvn_A_:_1 -0.105 0.002 -0.078 ``` --- class: small ```r summary(ma_3)$varcor ``` ``` ## Groups Name Std.Dev. ## p_id (Intercept) 0.1130 ## p_id.1 re1.B_given_A_c 0.1781 ## p_id.2 re1.rel_cond1 0.0843 ## p_id.3 re1.B_given_A_c_by_rel_cond1 0.1996 ## i_id (Intercept) 0.0181 ## i_id.1 re2.B_given_A_c 0.0737 ## i_id.2 re2.rel_cond1 0.0287 ## Residual 0.1664 ``` -- ```r summary(ma_3)$coefficients %>% zapsmall ``` ``` ## Estimate Std. Error df t value Pr(>|t|) ## (Intercept) -0.07 0.01 46.33 -4.98 0 ## B_given_A_c 0.61 0.04 18.74 17.25 0 ## rel_cond1 0.15 0.01 23.46 10.73 0 ## B_given_A_c:rel_cond1 0.18 0.03 86.54 6.19 0 ``` -- ```r fixef(ma_3$full_model) ``` ``` ## (Intercept) B_given_A_c rel_cond1 B_given_A_c:rel_cond1 ## -0.07283 0.60542 0.14979 0.18205 ``` --- class: small ## Skovgaard-Olsen et al. (2016): Follow-up Analyses .pull-left[ ```r nice(ma_3) %>% as.data.frame() ``` ``` ## Effect df F p.value ## 1 B_given_A_c 1, 18.74 297.48 *** <.0001 ## 2 rel_cond 1, 23.46 115.17 *** <.0001 ## 3 B_given_A_c:rel_cond 1, 86.54 38.35 *** <.0001 ``` ] .pull-right[ ```r library("emmeans") emm_options(lmer.df = "asymptotic") # or "Kenward-Roger" or "Satterthwaite" emmeans(ma_3, "rel_cond") ``` ``` ## NOTE: Results may be misleading due to involvement in interactions ``` ``` ## rel_cond emmean SE df asymp.LCL asymp.UCL ## PO 0.126 0.0202 Inf 0.0865 0.166 ## IR -0.196 0.0202 Inf -0.2359 -0.157 ## ## Degrees-of-freedom method: asymptotic ## Confidence level used: 0.95 ``` ] --- class: small ## Using `afex_plot` .pull-left[ ```r p1 <- afex_plot(ma_3, "rel_cond") ``` ``` ## Aggregating data over: p_id, i_id ``` ``` ## NOTE: Results may be misleading due to involvement in interactions ``` ```r p2 <- afex_plot(ma_3, "rel_cond", id = "p_id", data_geom = ggpol::geom_boxjitter, mapping = "fill") ``` ``` ## NOTE: Results may be misleading due to involvement in interactions ``` ] .pull-right[ ```r p2 ``` <!-- --> ] --- class: small ### Mixed Models in R: Follow-up Analyses ```r emm_options(lmer.df = "asymptotic") # or "Kenward-Roger" or "Satterthwaite" emtrends(ma_3, "rel_cond", var = "B_given_A_c") ``` ``` ## rel_cond B_given_A_c.trend SE df asymp.LCL asymp.UCL ## PO 0.787 0.0458 Inf 0.698 0.877 ## IR 0.423 0.0457 Inf 0.334 0.513 ## ## Degrees-of-freedom method: asymptotic ## Confidence level used: 0.95 ``` ```r fixef(ma_3$full_model)[2] + fixef(ma_3$full_model)[4] ``` ``` ## B_given_A_c ## 0.7875 ``` More examples of interplay between `mixed` or `lmer` with `emmeans`: - https://cran.r-project.org/package=afex/vignettes/afex_mixed_example.html - https://cran.r-project.org/package=emmeans/vignettes/sophisticated.html#lmer --- class: center, middle, inverse # Exercise 2.3: Maximal Random-Effects Structure (see `exercises\exercise2_MRE.Rmd` in folder or handout) **Do not fit the model! Only write done the maximal random-effects structure justified by the design.** --- class: small, inline-grey # Freeman, Heathcote, Chalmers, and Hockley (2010): Maximal Model - `task`: between participants (i.e., participants are nested within `task`), but within items (i.e., `task` is crossed with item) - `stimulus`: within participants (i.e., crossed with participants), but between items (i.e., each item is either word or non-word and thus `item` is nested within `stimulus`) - `density`: within participants, but between items - `frequency`: within participants, but between items - `length`: within participants, but between items ```r m_fhch <- mixed(log_rt ~ task*stimulus*density*frequency*length + (stimulus*density*frequency*length|id) + (task|item), fhch2010, method = "S", expand_re = TRUE) ## note: id RE-term has 24 parameters! Estimation of 276 correlations unrealistic! ``` --- class: small ### Example Data: Productivity Scores for Machines and Workers ```r data("Machines", package = "MEMSS") ``` - `Worker`: `Factor` giving unique identifier for the worker. - `Machine`: `Factor` with levels A, B, and C identifying machine brand. - `score`: Overall productivity score taking into account number and quality of components produced. Research question: Do the machines differ in their score? .pull-left[ <!-- --> ] -- .pull-right[ Fixed-effects model (without aggregation) ```r mach1 <- lm(score ~ Machine, Machines) car::Anova(mach1, type = 3) ``` ``` ## Anova Table (Type III tests) ## ## Response: score ## Sum Sq Df F value Pr(>F) ## (Intercept) 192139 1 5758.4 < 2e-16 *** ## Machine 1755 2 26.3 1.4e-08 *** ## Residuals 1702 51 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ``` ] --- ### Example Data: Productivity Scores for Machines and Workers ```r data("Machines", package = "MEMSS") ``` - `Worker`: `Factor` giving unique identifier for the worker. - `Machine`: `Factor` with levels A, B, and C identifying machine brand. - `score`: Overall productivity score taking into account number and quality of components produced. Research question: Do the machines differ in their score? .pull-left[ Fixed-effects model (without aggregation) ```r mach1 <- lm(score ~ Machine, Machines) car::Anova(mach1, type = 3) ``` ``` ## Anova Table (Type III tests) ## ## Response: score ## Sum Sq Df F value Pr(>F) ## (Intercept) 192139 1 5758.4 < 2e-16 *** ## Machine 1755 2 26.3 1.4e-08 *** ## Residuals 1702 51 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ``` ] .pull-right[ Mixed-model ```r (mach2 <- mixed(score~Machine+ (Machine|Worker), Machines)) ``` ``` ## Mixed Model Anova Table (Type 3 tests, KR-method) ## ## Model: score ~ Machine + (Machine | Worker) ## Data: Machines ## Effect df F p.value ## 1 Machine 2, 4 32.85 ** .003 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '+' 0.1 ' ' 1 ``` ] --- ### Mixed Models in R: Follow-up Analyses .pull-left[ **Fixed-effects model** ```r pairs(emmeans(mach1, "Machine"), adjust = "holm") ``` ``` ## contrast estimate SE df t.ratio p.value ## A - B -7.97 1.93 51 -4.138 0.0003 ## A - C -13.92 1.93 51 -7.228 <.0001 ## B - C -5.95 1.93 51 -3.090 0.0032 ## ## P value adjustment: holm method for 3 tests ``` ] .pull-right[ **Mixed-effects model** ```r emm_options(lmer.df = "Satterthwaite") ## or "Kenward-Roger" pairs(emmeans(mach2, "Machine"), adjust = "holm") ``` ``` ## contrast estimate SE df t.ratio p.value ## A - B -7.97 2.42 5.00 -3.290 0.0435 ## A - C -13.92 1.54 5.01 -9.044 0.0008 ## B - C -5.95 2.44 5.01 -2.434 0.0590 ## ## P value adjustment: holm method for 3 tests ``` ] --- class: center, middle, inverse # Exercise 2.4: Many Labs 2 # (Last Exercise: `exercise_2.4_ML2.Rmd` or handout) --- class: small > **Many Labs 2 abstract:** We conducted preregistered replications of 28 classic and contemporary published findings with protocols that were peer reviewed in advance to examine variation in effect magnitudes across sample and setting. Each protocol was administered to approximately half of 125 samples and 15,305 total participants from 36 countries and territories. Using conventional statistical significance (p < .05), fifteen (54%) of the replications provided evidence in the same direction and statistically significant as the original finding. With a strict significance criterion (p < .0001), fourteen (50%) provide such evidence reflecting the extremely high powered design. Seven (25%) of the replications had effect sizes larger than the original finding and 21 (75%) had effect sizes smaller than the original finding. > The median comparable Cohen's d effect sizes for original findings was 0.60 and for replications was 0.15. Sixteen replications (57%) had small effect sizes (< .20) and 9 (32%) were in the opposite direction from the original finding. > Across settings, 11 (39%) showed significant heterogeneity using the Q statistic and most of those were among the findings eliciting the largest overall effect sizes; only one effect that was near zero in the aggregate showed significant heterogeneity. Only one effect showed a Tau > 0.20 indicating moderate heterogeneity. Nine others had a Tau near or slightly above 0.10 indicating slight heterogeneity. Moderation tests indicated that very little heterogeneity was attributable to the order in which the tasks were performed or whether the tasks were administered in lab versus online. > Exploratory comparisons revealed little heterogeneity between Western, educated, industrialized, rich, and democratic (WEIRD) cultures and less WEIRD cultures (i.e., cultures with relatively high and low WEIRDness scores, respectively). Cumulatively, variability in the observed effect sizes was attributable more to the effect being studied than to the sample or setting in which it was studied. For paper and materials see: https://osf.io/8cd4r/ --- class: small - Goal: Reanalyze data from 3 samples and 1 task, syllogisms, used in Many Labs 2. - Between-subjects manipulation supposedly affected fluency of syllogisms: Hard to read vs. easy to read font. - Hypothesis: Decreased fluency makes individuals think harder and thus they solve more syllogisms. Syllogisms are logical arguments with two premises. For example: > All dentists are golfers. > Some dentists are not tennis players. > What, if anything, follows Participants have to select the correct answer (what follows with logical necessity assuming the premises listed above are true) among a set of 9 possible conclusions listed below: 1. All golfers are tennis players. 2. No tennis players are golfers. 3. All tennis players are golfers. 4. No golfers are tennis players. 5. Some golfers are not tennis players. 6. Some golfers are tennis players. 7. Some tennis players are not golfers. 8. Some tennis players are golfers. 1. Cannot reach a conclusion. - Main tasks: Identify maximal random-effects structure, fit data with mixed model, evaluate whether hypothesized pattern was observed. For more see exercise sheet. --- class: center, middle, inverse # Additional Topics --- class: small .pull-left[ ### Intraclass Correlation Coefficient (ICC) Assumption of mixed models: Data points from same unit of observation more similar to each other than unrelated data point. **Intraclass correlation coefficient (ICC)**: Measure of similarity for data points of a given random-effects grouping factor ranging from 0 to 1: `$$\rho=\frac{\sigma^2_S}{\sigma^2_S+\sigma^2_\epsilon}$$` > The intraclass correlation `\(\rho\)` can also be interpreted as the expected correlation between two randomly drawn units that are in the same group. (Hox, 2010, p. 15) ] .pull-right[ ```r m1 <- lmer(if_A_then_B_c ~ 1 + (1|p_id), dat2) # summary(m1) # Random effects: # Groups Name Variance Std.Dev. # p_id (Intercept) 0.00572 0.0757 # Residual 0.14607 0.3822 # Number of obs: 752, groups: p_id, 94 0.00572 / (0.0057+0.1461) ``` ``` ## [1] 0.03768 ``` ```r library("sjstats") icc(m1) ``` ``` ## # Intraclass Correlation Coefficient ## ## Adjusted ICC: 0.038 ## Conditional ICC: 0.038 ``` ] --- class: small ### Intraclass Correlation Coefficient (ICC) .pull-left[ ```r m1 <- lmer(if_A_then_B_c ~ 1 + (1|p_id), dat2) # summary(m1) # Random effects: # Groups Name Variance Std.Dev. # p_id (Intercept) 0.00572 0.0757 # Residual 0.14607 0.3822 # Number of obs: 752, groups: p_id, 94 icc(m1) ``` ``` ## # Intraclass Correlation Coefficient ## ## Adjusted ICC: 0.038 ## Conditional ICC: 0.038 ``` ] .pull-right[ ```r m2 <- lmer(if_A_then_B_c ~ 1 + (rel_cond:B_given_A_c|p_id), dat2) # summary(m2) # Groups Name Variance Std.Dev. Corr # p_id (Intercept) 0.0398 0.200 # rel_condPO:B_given_A_c 1.0186 1.009 -0.94 # rel_condIR:B_given_A_c 0.3262 0.571 -0.48 0.75 # Residual 0.0570 0.239 icc(m2) ``` ``` ## zero-length inputs cannot be mixed with those of non-zero length ``` ``` ## [1] NA ``` ```r ## Caution! ICC for random-slope-intercept models usually ## not meaningful. See 'Note' in `?icc`. ``` ] - ICC can be useful to determine if mixed models necessary or to determine how multilevel-clustering effects response. - ICC often not very useful for random-slope models (Goldstein et al., 2002), direct inspection of SDs often more helpful. --- class: inline-grey, small .pull-left[ ## LMMs: Residuals ```r dat2$residuals <- residuals(ma_3$full_model) ggplot(dat2, aes(sample = residuals)) + stat_qq() + stat_qq_line() + theme_bw() + theme(text=element_text(size=18)) ``` <!-- --> ] .pull-right[ - We can inspect normality assumption of LMM using QQ-plots via `residuals()` - For `afex::mixed` make sure to pass `full_model` slot to `residuals()`. - Alternatively, use `qqmath.merMod()` (see `?qqmath.merMod`). - Here, very heavy tails in residuals (i.e., leptokurtic) and no transformation can help. Without more ambitious model we have to settle. - We know normality assumption must be violated for data on restricted scale - We are not interested in coefficients and prediction - Inference agrees with visual impression <!-- --> ] --- class: inline-grey # GLMMs: Mixed-models with Alternative Distributional Assumptions - Not all data can be reasonable described by a Normal distribution. - Generalized-linear mixed models (GLMMs; e.g., Jaeger, 2008) allow for other distributions: - Binomial distribution: Repeated-measures logistic regression - Poisson distribution for count data - Gamma distribution for non-negative data (e.g., RTs) - ... - GLMMs require specification of residual distribution (`family`) and link function. - Link function determines how values on untransformed scale are mapped onto response scale. - Specification of random-effects structure conceptually identical as for LMMs. - GLMMs only allow two methods for hypothesis testing: `"LRT"` or `"PB"`. - Inspection of residuals/model fit more important for GLMMs than for LMMs: R package [`DHARMa`](https://cran.r-project.org/package=DHARMa) - Can be fit with `lme4::glmer` or `afex::mixed`, both require `family` argument (e.g., `family = binomial`). --- class: small ### GLMM Example ```r data("fhch2010") fhch2 <- droplevels(fhch2010[fhch2010$task == "lexdec", ] ) gm1 <- mixed(correct ~ stimulus + (stimulus||id) + (stimulus||item), fhch2, family = binomial, # implies: binomial(link = "logit") method = "LRT", expand_re = TRUE) # alt: binomial(link = "probit") gm1 ## Mixed Model Anova Table (Type 3 tests, LRT-method) ## ## Model: correct ~ stimulus + (stimulus || id) + (stimulus | item) ## Data: fhch2 ## Df full model: 7 ## Effect df Chisq p.value ## 1 stimulus 1 1.19 .28 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '+' 0.1 ' ' 1 ## Warning messages: [...] emmeans(gm1, "stimulus", type = "response") ## stimulus prob SE df asymp.LCL asymp.UCL ## word 0.9907 0.002323 NA 0.9849 0.9943 ## nonword 0.9857 0.003351 NA 0.9774 0.9909 ## ## Confidence level used: 0.95 ## Intervals are back-transformed from the logit scale ``` - Removing correlations does not remove warnings. Likely reason: Data at boundary. - Alternative specification for Binomial model: DV is proportion + `weight` (= N observations) --- ### Summary - Mixed models allow accounting for dependencies originating from clustered data via random effects. - Fixed effects represent the overall/average effect; random effects add offset to specific fixed effects. - Random-effects parameters are variances of offsets and covariances among different random-effects parameters. - Random-effects assumed to follow normal distribution thereby implementing partial-pooling / hierarchical-shrinkage (regularization). - Mixed-model analysis should start with maximal model which includes random slopes for all effects that vary within a random-effects grouping factor. - If maximal model fails to converge or is singular/degenerate: Start by removing correlation, then highest-order effects. - Linear mixed models (LMMs) can be extended to generalized linear mixed models (GLMMs) that support different link function and residual distribution (via `glmer` or `mixed`). - Bayesian estimation possible: `rstanarm::stan_lmer`, `blme`, `MCMCglmm`, or `brms`. - More powerful: generalized additive mixed models (GAMM; Baayen, Vasisth, Kliegl, & Bates, 2017). - An overview of these topics is also provided in: Singmann and Kellen (in press). An Introduction to Mixed Models for Experimental Psychology. In D. H. Spieler & E. Schumacher (Eds.), *New Methods in Neuroscience and Cognitive Psychology*. Psychology Press. http://singmann.org/download/publications/singmann_kellen-introduction-mixed-models.pdf --- class: small ### References Mixed Modeling: - Singmann, H., & Kellen, D. (in press). An Introduction to Mixed Models for Experimental Psychology. In D. H. Spieler & E. Schumacher (Eds.), *New Methods in Neuroscience and Cognitive Psychology*. Psychology Press. http://singmann.org/download/publications/singmann_kellen-introduction-mixed-models.pdf - Baayen, H., Vasishth, S., Kliegl, R., & Bates, D. (2017). The cave of shadows: Addressing the human factor with generalized additive mixed models. *Journal of Memory and Language*, 94, 206-234. https://doi.org/10.1016/j.jml.2016.11.006 - Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: Keep it maximal. *Journal of Memory and Language*, 68(3), 255-278. https://doi.org/10.1016/j.jml.2012.11.001 - Bates, D., Kliegl, R., Vasishth, S., & Baayen, H. (2015). *Parsimonious Mixed Models.* arXiv:1506.04967 [stat]. http://arxiv.org/abs/1506.04967 - Goldstein, H., Browne, W., & Rasbash, J. (2002). Partitioning Variation in Multilevel Models. *Understanding Statistics*, 1(4), 223-231. https://doi.org/10.1207/S15328031US0104_02 - Hox, J. J. (2010). *Multilevel analysis: techniques and applications.* New York: Routledge. - Jaeger, T. F. (2008). Categorical data analysis: Away from ANOVAs (transformation or not) and towards logit mixed models. _Journal of Memory and Language_, 59(4), 434-446. https://doi.org/10.1016/j.jml.2007.11.007 - Matuschek, H., Kliegl, R., Vasishth, S., Baayen, H., & Bates, D. (2017). Balancing Type I error and power in linear mixed models. *Journal of Memory and Language*, 94, 305-315. https://doi.org/10.1016/j.jml.2017.01.001 - https://tjmahr.github.io/plotting-partial-pooling-in-mixed-effects-models/ - https://cran.r-project.org/package=DHARMa --- class: small ### References Example Data: - Skovgaard-Olsen, N., Singmann, H., & Klauer, K. C. (2016). The relevance effect and conditionals. *Cognition*, 150, 26-36. https://doi.org/10.1016/j.cognition.2015.12.017 --- class: small ### Residuals .pull-left[ ```r plot(m_max, resid(.,scaled=TRUE) ~ B_given_A | rel_cond) ``` <!-- --> ] .pull-right[ ```r lattice::qqmath(m_max) ``` <!-- --> ] ```r plot(m_max, p_id ~ resid(., scaled=TRUE) ) plot(m_max, resid(., scaled=TRUE) ~ fitted(.) | rel_cond) ?plot.merMod ``` - https://cran.r-project.org/doc/contrib/Faraway-PRA.pdf - https://htmlpreview.github.io/?https://github.com/bbolker/iiscvisit/blob/master/workshops/mixedlab.html --- ### Interpreting Residuals - Zuur et al. (2009). *Mixed Effects Models and Extensions in Ecology with R.* Springer. [Chapter 2] - Farraway (2002). *Practical Regression and Anova using R*. https://cran.r-project.org/doc/contrib/Faraway-PRA.pdf [Chapter 7] ### Further Diagnostics - http://janhove.github.io/analysis/2018/04/25/graphical-model-checking - https://cran.r-project.org/web/packages/influence.ME/index.html - https://cran.r-project.org/web/packages/DHARMa/index.html